
중국의 스타트업 딥시크(DeepSeek)가 올해 1월 내놓은 생성형 AI 모델 'R1'으로 세계적인 AI 컴퓨팅 리딩 기업인 엔비디아(NVIDIA)의 주가가 곤두박질치는 등 AI 생태계에 지각변동이 일고 있습니다. AI 산업 수혜주인 브로드컴과 오라클, 티에스엠시(TSMC) 등도 덩달아 주가 폭락을 면지 못했는데요. 딥시크의 R1은 어떻게 기존 AI 선두 기업들의 시장경쟁력에 의문을 띄울 수 있었을까요? 생성형 AI 시대의 문을 연 챗GPT와 비교해 보며, 딥시크 R1의 차이점과 강점, 영향력을 짚어보겠습니다.
결핍이 만든 '혁신'일까?
놀랍게도 딥시크는 설립 만 2년도 되지 않은 신생 기업입니다. 퀀트(Quant) 투자1) 전문 기업인 '하이플라이어(High-Flyer)'가 2023년 5월에 만든 자회사로 AI를 전문적으로 연구하는 스타트업인데요. 연혁이 그리 길지 않은데다, 직원 수도 200명 미만의 작은 기업이 오픈AI의 최신 모델인 오픈AI-o1-1217과 거의 대등한 성능을 보인 모델을 출시해 세계를 놀라게 하고 있습니다.
생성형 AI는 많은 인력과 조 단위의 고비용을 들여 고사양의 GPU(그래픽 처리 장치)으로 학습해야만 만들 수 있다는 게 통념이었습니다. 스탠퍼드 2024년 AI 인덱스 리포트에 따르면 구글의 제미나이 울트라(Gemini Ultra)가 한화 약 2조 7천억 원, 오픈AI의 챗GPT-4는 약 1조 1천억 원을 들였는데요. 그러나 딥시크는 한화 약 80억 원의 비용을 썼다고 주장하고 있습니다. (이것이 사실이라면, 오픈AI의 챗GPT-4 대비 18분의 1 수준밖에 사용하지 않은 것이죠.) 개발 비용이 적게 든 것은 딥시크가 저사양의 GPU를 주로 사용했기 때문입니다. 딥시크는 미국의 수출 제한 조치로 엔비디아의 고성능 GPU인 H100, H200을 자유롭게 활용할 수 없어, 보급형인 저사양의 H800을 사용할 수밖에 없었습니다. 미국의 주요 AI 모델이 약 1만 6천 개의 고사양 GPU를 사용하는 것으로 알려졌는데요. 딥시티는 저사양 GPU 수천 개로 R1 모델을 훈련했다고 합니다.
딥시크 R1이 저사양 GPU로 높은 성능을 내는 것에 대해, 전문가들은 MoE(Mixture-of-Experts) 아키텍처가 중요한 역할을 했을 것으로 추정합니다. MoE는 특정 작업에 특화된 LLM(거대 언어 모델)을 한데 모은 후, 작업별로 필요한 LLM만 활성화하는 기술입니다. 딥시크 R1의 파라미터(매개변수)는 6,710억 개이지만 작업 시 활성화되는 것은 340억 개로 설계됐습니다. 모든 파라미터를 한 번에 쓰지 않기에 메모리 사용량은 낮고 작업 속도는 빠른 것입니다. 한마디로 작업마다 특화된 소규모의 전용 LLM만 활성화하여 AI 학습 비용을 절감하는 것이죠!
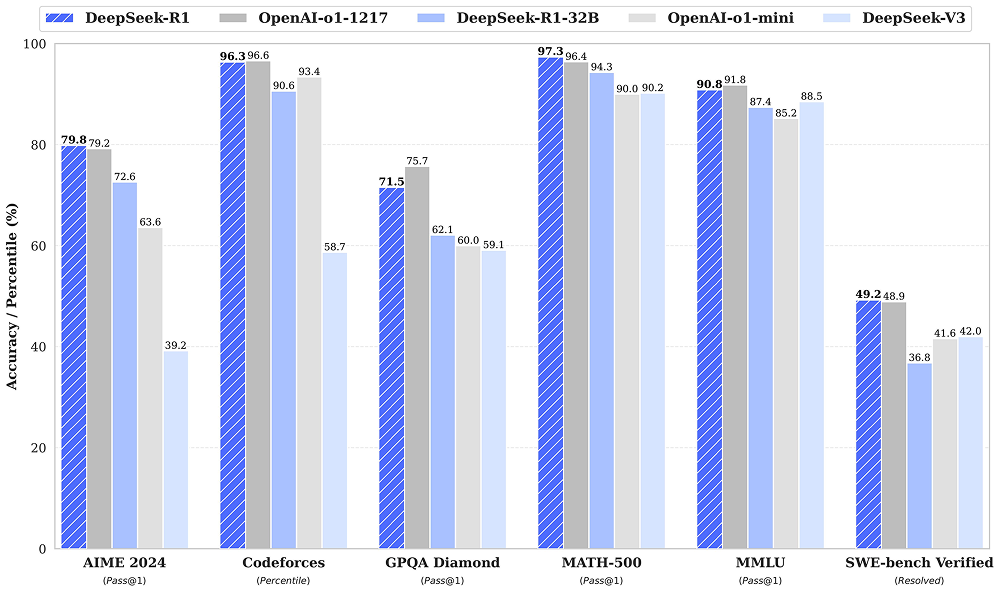
여러 측정 항목에서 오픈AI의 o1 모델과 대등한 성능을 보인 R1(출처 : 딥시크 깃허브)
여기서, R1과 동시 공개된 DeepSeek-R1-Zero 모델의 개발 과정을 잠시 살펴보려 합니다. 생성형 AI는 사용자가 원하는 수준의 답변을 할 수 있도록 지도 미세 조정 과정(Supervised Fine-Tuning, SFT)을 거치게 됩니다. 사람이 직접 만든 질문과 답변으로 구성된 소규모 데이터 모음을 이용해 학습하는 과정인데요. 고품질의 데이터를 만들려면 인력과 비용 리소스가 많이 투자되어야 합니다. 그런데 R1-Zero 모델은 SFT 단계를 최소화하고 스스로 성능을 향상시키는 강화 학습(GRPO)2)으로 개발했습니다. 인간이 만든 예시 데이터에 의존하지 않고 순수 RL(Reinforcement Learning)3)로만 훈련한 것인데요. AI가 추론을 통해 정답을 찾았을 때 가점을 부여하는 ‘정확도 보상(Accuracy Rewards)’을 적용해 성능을 높인 것으로 알려졌습니다. 비용이 많이 드는 SFT 단계 대신 강화 학습에 의존해 개발한 DeepSeek-R1-Zero 모델은 아쉽게도 자연어 친화적인 답변을 잘 도출하지 못하는 한계가 있었는데요. R1-Zero 모델에 양질의 소규모 데이터로 초기 학습하여 사람이 잘 이해할 수 있는 답변을 생성하는 버전이 바로 R1입니다. 적은 돈과 짧은 기간 내 고효율의 AI 모델을 만든 딥시크는 출시 1주일만에 미국에서 가장 많이 다운로드된 무료 앱 1위에 등극했습니다.
챗GPT와 닮은 듯 다른 딥시크 R1
| |
챗GPT |
딥시크 R1 |
| 공통점 |
⁕ 대화형 AI 플랫폼으로 텍스트 기반 질문에 답변을 제공해요!
⁕ 콘텐츠 생성, 질의 응답, 분석, 코딩 등 다방면에 활용할 수 있어요!
⁕ 영어 등 다국어 지원으로 전 세계 사용자를 타깃으로 하고 있어요!
|
| 차이점 |
[유/무료 제공]
유/무료 버전간 상당한 성능 차이가 존재
|
[무료 제공]
무료 버전이지만 챗GPT 유료 버전과 비슷한 성능
|
|
[추론 과정 미제공]
도출된 답변의 추론 과정을 알 수 없음
|
[추론 과정 시각화]
답변 도출의 추론 과정 공개 / 이를 통해 프롬프트 수정 용이
|
|
[연동과 확장에 용이]
챗GPT 플러그인, API 활용이 가능
|
[확장에 제한적]
챗GPT 대비 확정성은 다소 부족함
|
|
[웹 친화성]
모바일 UI도 제공하지만 웹 친화성이 더 높은 편
|
[모바일 친화성]
챗GPT 대비 더욱 간편하고 최적화된 모바일 환경
|
|
[보호 장치에 투자]
보안 등 규정 준수에 많은 리소스 투자, 다양한 보호 장치 마련
|
[보안 우려]
악의적 목적에 따른 정보 유출 가능성 우려
|
① 무료 도구 중 최고일 가능성!
딥시크의 R1은 챗GPT를 능가하는 파라미터 수로 더욱 복잡하고 정교한 작업을 수행할 수 있습니다. 일반적인 질의 응답은 물론, 창의적 글쓰기와 편집, 요약 등 다양한 과제에서 뛰어난 성능이 확인되었다고 하는데요. 기술적 성능 비교에서도 R1은 초당 150토큰을 처리하며 챗GPT-4 대비 1.2나 빠른 응답속도를 보였고, 최대 8,192토큰의 대화 기록을 유지할 수 있어서 챗GPT-4의 2배 수준으로 맥락을 기억할 수 있다고 합니다.
② 보안 취약성 주의!
가성비 AI로 급상승 중인 R1이지만, 보안 취약성으로 우려의 목소리가 커지고 있어요. 딥시크는 자사 서비스의 개인정보 처리방침에 사용자 아이디와 장비명, IP, 쿠키 등을 수집해 중국 내 서버에 보관한다고 명시했는데요. 이탈리아와 프랑스, 영국, 독일 등 유럽 각국에서는 개인정보 수집 및 처리 실태를 확인 중이며, 우리나라의 개인정보보호위원회도 실태 파악을 예고했습니다. (2025년 1월 31일 기준)
③ 개방형 모델로 선택지 부여!
챗GPT는 개발 소스가 외부에 공개되지 않는 폐쇄형 모델인 반면 딥시크는 개방형 모델입니다. R1 모델 가중치(weights)와 매개변수 등 핵심 기술을 오픈소스로 공개해 누구나 자유롭게 다운로드해 수정 및 개선할 수 있도록 했는데요. 딥시크의 LLM을 다운로드해 무료로 실행하고, LLM을 미세조정하는 추가 훈련으로 특화된 성능을 기대할 수 있습니다. 챗GPT로는 불가능한 일이기에 다양한 업계에서 관심을 갖고 활용할 가능성이 높습니다.
딥시크발 변화의 물결
📌 빅테크 기업들의 발빠른 태세전환
마이크로소프트와 아마존웹서비스(AWS), 메타(META)는 딥시크 R1을 활용해 자사 서비스와 모델 개발을 업그레이드하는 것으로 알려졌습니다. 이들은 챗GPT 개발사인 오픈AI에 대한 의존도를 줄이기 위해 R1을 적극적으로 채택한 것인데요. 기업 데이터 제공 업체인 줌인포에 따르면 오픈AI o1에서 딥시크 R1으로 교체 시, AI 비용을 3분의 2 수준까지 줄일 수 있을 것으로 전망했습니다.
📌 LLM의 상향 평준화 전망
기업들이 모두 오픈AI 수준의 AI 모델 성능에 쉽게 도달할 수 있다면 시장 경쟁은 포화 상태에 이를 가능성이 높습니다. LLM의 상향 평준화가 예상되는 대목인데요. 이렇게 된다면 AI 모델의 차별화 요소는 ‘사용자 경험의 최적화’로 옮겨질 가능성이 높습니다. AI 고유의 고객 데이터를 활용한 맞춤형 서비스를 제공한다거나 고객 친화적인 UI 환경 설계가 중요해질 것입니다. 또 기존 비즈니스 모델과의 유연한 통합과 결합으로 경쟁력을 높일 수 있을 것입니다. 같은 AI 성능이라도 브랜드 정체성이나 감성을 어떻게 부여하느냐에 따라 남다른 경험을 제공할 수도 있습니다.
📌 규모의 경쟁에서 창의성과 최적화 씨름으로
고품질의 GPU 리소스가 없어도 낮은 사양의 GPU로 세계적 수준의 AI 모델을 개발할 수 있다는 가능성이 검증됐습니다. AI 기술 경쟁은 이제 규모의 경쟁을 탈피하게 되었는데요. 독창적이고 전문적인 데이터를 확보하는 것과 더불어 적은 리소스로 빠른 학습이 가능한 최적화된 알고리즘 기술 확보에 주력해야 합니다. 또 AI를 비즈니스에 접목하는 것에 있어 창의적 사고와 혁신적 기획력이 중요해질 것입니다. 모델 확보가 아니라 어떤 가치를 만들 것이냐가 더 중요한 시대가 되는 것이죠!
1) 수학, 통계, 프로그래밍을 이용해 자산 운용 및 투자 전략을 세우는 방식
2) Group Relative Policy Optimization
3) 시행착오를 통해 스스로 학습하는 방식, 보상에 따라 행동을 개선
보안 걱정 없는 이커머스 전용 sLLM이 궁금하다면? 아래 콘텐츠를 둘러보세요!
LLM과 sLLM의 차이, 플래티어 POLAR로 쉽게 이해하기 (클릭!)
